迪士尼发布首个百万像素高分辨率换脸算法 拍电影可以安排了
原创 关注前沿科技 量子位
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
换脸这件事,从未如此高清。
 最流行的开源deepfake模型DeepFakeLab,在今年的更新中,最大分辨率也只达到了320×320。
最流行的开源deepfake模型DeepFakeLab,在今年的更新中,最大分辨率也只达到了320×320。
而这只来自迪士尼和ETHZ的全新deepfake,在保持高度流畅这一优良传统的同时,还一举把分辨率拉高到了1024×1024的水平。
这也是deepfake的分辨率水平首次达到百万像素。
这下,换脸之后,每一根眉毛都仍然清晰可见。
 动图画质略有损失,用静态图来感受一下这个清晰度:
动图画质略有损失,用静态图来感受一下这个清晰度:
 难怪网友忍不住惊呼:鹅妹子嘤。
难怪网友忍不住惊呼:鹅妹子嘤。
为特效而生的高分辨率deepfake
在此之前,deepfake技术的改进重点主要在平滑换脸效果,而不是提高分辨率。
但320×320这样的分辨率下,手机上看换脸效果可能行云流水看不出破绽,换到大屏幕上,缺陷就会很明显。
 为了提高分辨率,迪士尼的这项研究主要引入了逐步训练的多向梳状网络,并提出了一个完整的人脸交换管道,包括保留光线和对比度的混合方法,以减少视频常出现不真实的抖动,生成时间上稳定的视频序列。
为了提高分辨率,迪士尼的这项研究主要引入了逐步训练的多向梳状网络,并提出了一个完整的人脸交换管道,包括保留光线和对比度的混合方法,以减少视频常出现不真实的抖动,生成时间上稳定的视频序列。
具体而言,分为以下几个步骤:
首先,对输入人脸进行裁剪和归一化预处理,将人脸归一化为1024×1024分辨率,并保存归一化参数。
而后,预处理过的图像会被输入到通用编码器中,用相应的解码器Ds进行解码。
最后,用多频段混合方法来交换目标人脸和源人脸。
 渐进式训练的多向梳状网络
渐进式训练的多向梳状网络
在网络架构上,迪士尼采用了单个编码器、多个解码器的方案,称作“梳子模型”。
即,网络的编码部分是共享的,而解码路径则分成P个域。
 这样一来,一个模型就能同时处理多个源-目标对。
这样一来,一个模型就能同时处理多个源-目标对。
并且,实验表明,与双向模型相比,多向训练模型可以提高表达的保真度。
由于多向编码器允许生成不同的输出,这些输出既可以对应不同的身份,也可以对应不同照明条件下的同一张脸。
此外,还有一重优势是,相比于双向网络,使用单一网络的训练时间能明显减少。
网络的训练,则采取渐进式机制。
首先,对高分辨率输入数据进行下采样,形成粗糙的低分辨率图像,先用这些低分辨率图像进行训练。此后,逐步在训练中加入高分辨率图像,逐渐扩大网络的容量。
消除时间伪影
为了消除可见的时间伪影,研究人员还提出了一种稳定标志物定位算法的方法。
具体而言,是对人脸进行初始检测和对其,并标记人脸边界框的宽度w 。
然后,通过在图像平面的不同方向上扰动βw个像素,来重新初始化原始边界框n次。
研究人员发现,在1024×1024分辨率下,β=0.05和n=9时,可以消除所有可见的时间伪影。
保留光线和对比度的混合方法
不过,即使人脸已经完全对齐,姿势和面部表情也完全匹配,光度失准等问题,依然会造成换脸效果的不和谐。
比如出现明显的接缝。
 针对这个问题,研究人员采用了保留光线和对比度的多频段混合方法,并强制要求边界平滑效果只传播人脸内部,确保外侧的人脸轮廓不会被平滑掉。
针对这个问题,研究人员采用了保留光线和对比度的多频段混合方法,并强制要求边界平滑效果只传播人脸内部,确保外侧的人脸轮廓不会被平滑掉。
与常用的泊松混合(Poisson blending)方法相比,在目标人脸图像和源人脸图像光照不同的情况下,该方法消除伪影的效果更好。
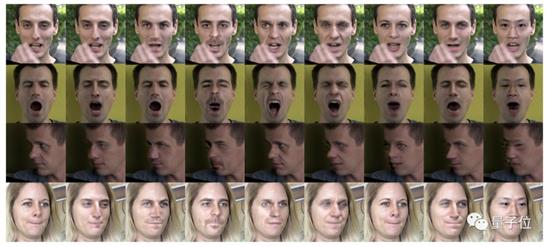
 所以,这个高清deepfake的效果应该如何评价?
所以,这个高清deepfake的效果应该如何评价?
直接看对比:
 deepfake登上大荧幕,指日可待
deepfake登上大荧幕,指日可待
不过,研究人员也指出,这个高清deepfake仍有局限性。
从展示的示例中可以看出,大部分人脸图像都是正对镜头的。
夸张的表情、极端的角度和光线,仍然会导致模糊和伪影。
 但分辨率的提升,依然给deepfake带来了全新的商业可能性。
但分辨率的提升,依然给deepfake带来了全新的商业可能性。
迪士尼就曾经在《星球大战》系列电影《侠盗一号》里,用特效换脸技术让已故演员Peter Cushing和Carrie Fisher重返荧幕。
不过,采用传统特效技术,通常要花费数月时间,才能获得几秒钟的画面,成本十分高昂。
相比之下,构建原始模型之后,deepfake在数小时之内就能完成换脸视频的制作。
看来,deepfake技术登上大屏幕,或许离实现不远了。
参考链接:
论文地址:
http://studios.disneyresearch.com/2020/06/29/high-resolution-neural-face-swapping-for-visual-effects/
https://www.theverge.com/2020/6/29/21306889/disney-deepfake-face-swapping-research-megapixel-resolution-film-tv
— 完 —原标题:《用deepfake拍电影可以安排了:迪士尼发布首个百万像素高分辨率换脸算法》
阅读原文
新闻推荐
中国金鸡百花电影节于2019年正式落户福建厦门一年后,位于厦门的集美大学电影学院正式揭牌。据集美大学官网消息,6月28日上...